In freemium games, player churn – when users disengage without officially quitting – can drastically impact revenue. About 60% of players stop after one day, and 70-90% leave within 10 days. What’s more, only 1.6% of players make in-app purchases, yet these account for 90% of revenue. Losing even a few high-spenders can hurt profitability. But improving retention by just 5% can quadruple profits.
To address this, churn prediction models identify at-risk players early, enabling targeted re-engagement strategies. Popular models include:
- Logistic Regression: Simple, interpretable, and fast to train. Great for quick insights but less effective with complex patterns.
- Random Forest: Accurate and handles diverse data well. Slightly slower but ideal for general prediction needs.
- XGBoost: High performance with sequential tree boosting but requires careful tuning.
- Support Vector Machines (SVM): Effective for smaller datasets but struggles with scalability.
- Neural Networks: Handles complex behaviors but demands significant computational resources and lacks transparency.
Each model has strengths and trade-offs. For example, Random Forest is often the top choice for balancing accuracy and usability, while Logistic Regression works well for simpler needs. Choosing the right model depends on your game’s data, player behavior, and goals.
Building a Machine Learning Pipeline to Predict Customer Churn
1. Logistic Regression
Logistic regression is a powerful tool for binary classification, often used to predict player churn. By analyzing gameplay data, it estimates the likelihood of a player leaving the game. This probabilistic approach allows you to rank players by their churn risk, enabling targeted retention efforts on those most likely to quit[3][4].
Accuracy
In April 2024, researchers David David and Amalia Zahra from Universitas Bina Nusantara studied a dataset from the Steam API, which included 418 unique players and a 15% churn rate. Their logistic regression model achieved an impressive 95% accuracy. This performance matched Support Vector Machines and came just shy of Random Forest’s 96%[5]. While ensemble methods like Random Forest might slightly edge it out, logistic regression remains a reliable choice for most freemium games.
Beyond its accuracy, logistic regression stands out for its transparency, making it a valuable tool for understanding player behavior.
Interpretability
One of the standout features of logistic regression is its clarity. The model assigns coefficients to each behavioral factor, such as active play duration or the ratio of consecutive play sessions. These coefficients provide insights into how specific gameplay elements influence churn probability. This makes it especially useful for explaining churn predictions to stakeholders or identifying areas in the game that may need improvement[3].
Training Time
Logistic regression is also computationally efficient, requiring far less processing power compared to deep learning models[2]. This efficiency is crucial for freemium games that handle large datasets. It enables quick predictions, particularly during the critical first 24 to 72 hours when players are most likely to churn.
These advantages make logistic regression a practical choice for early-stage churn prediction.
Suitability for Freemium Game Data
In the freemium game model, where preventing early churn is vital, logistic regression serves as an excellent baseline. It performs well with basic behavioral metrics like playtime, session length, and session intervals – data that most games already collect. However, its main limitation lies in its assumption of a linear relationship between variables and churn probability. This can make it less effective at capturing more complex, non-linear player behaviors[8].
For straightforward retention challenges, logistic regression is an efficient, interpretable, and practical solution, especially during the early days of a player’s lifecycle.
2. Random Forest
Random Forest takes a different approach from logistic regression by combining multiple decision trees to analyze non-linear player behaviors. Instead of depending on a single tree, it aggregates predictions from many, making it a powerful tool for capturing complex patterns in player activity.
Accuracy
Random Forest consistently delivers strong results in churn prediction. For example, in April 2024, researchers David David and Amalia Zahra from Universitas Bina Nusantara tested the model on a Steam API dataset of 418 players with a 15% churn rate. The model achieved an impressive 96% accuracy, outperforming Logistic Regression and Support Vector Machines, which both reached 95% accuracy [5]. Similarly, a May 2020 case study published in IEEE Transactions on Games analyzed data from the freemium strategy game The Settlers Online. Using a sliding windows approach, Random Forest achieved 97% accuracy and an Area Under the Curve (AUC) value exceeding 0.99 [1]. Another study in December 2022 by Guan-Yuan Wang from Vilnius University focused on high-value players in a casual mobile farming game. The Random Forest model, configured with 500 trees and 11 predictors per split, achieved an AUC of 0.930 and identified churners with 86.32% sensitivity [7].
Interpretability
While it doesn’t offer the straightforward coefficient transparency of logistic regression, Random Forest provides valuable insights through feature importance rankings. These rankings identify which behaviors – like login frequency, session intervals, or in-game purchases – are the strongest predictors of churn. The model automatically prioritizes relevant variables and ignores less useful ones, all without requiring feature scaling. This capability makes it particularly effective when working with diverse behavioral data [10].
"Ensemble methods (random forest, gradient boosting) … maintain a good balance between accuracy and interpretability." – Bombora [6]
Training Time
Building multiple decision trees requires more computational resources compared to logistic regression. However, Random Forest can distribute this workload across multiple processors, making it suitable for real-time analysis – even in games with millions of active users [11].
Scalability
Scaling Random Forest for large datasets can be challenging, but strategies like breaking data into smaller time frames help manage these difficulties. For instance, between January 2018 and January 2022, a European game developer analyzed 80 million players from an interactive storytelling game. By creating smaller datasets for specific time periods, they achieved prediction accuracies ranging from 66% to 95%, depending on the observation and prediction windows [2]. The sliding windows approach, which separates observation and prediction periods, has proven essential for maintaining accuracy, as seen in studies like The Settlers Online [1].
Suitability for Freemium Game Data
Random Forest is particularly well-suited for freemium games. It handles diverse telemetry data – such as session intervals and in-game purchases – without requiring custom feature scaling [7]. The model is also adept at managing imbalanced datasets, where churners often make up only a small percentage of the player base [7].
In casual freemium games, where about 60% of players quit after just one day, Random Forest’s ability to quickly analyze early player behaviors and detect disengagement patterns makes it an invaluable tool for improving retention [2].
Next, we’ll explore Gradient Boosting Machines (XGBoost) and how they push predictive performance even further with boosting strategies.
3. Gradient Boosting Machines (XGBoost)
Building on the strengths of Random Forest, XGBoost enhances churn prediction by constructing trees sequentially. It uses an additive approach and leverages a second-order Taylor expansion to refine corrections from earlier trees, boosting overall model performance [12].
Accuracy
In a study involving 34,769 high-value players from a casual mobile farming game, XGBoost (configured with 300 trees and a maximum depth of 6) delivered impressive results: 91.78% accuracy and an AUC of 0.915, outperforming models like KNN, RDA, and Logistic Regression [7]. It also achieved 84.62% sensitivity in identifying churners [7]. Another notable example comes from a 2018 competition hosted by NCSOFT, which provided 100 GB of game logs from 10,000 players of Blade & Soul. During this event, participants focused on predicting churn during the game’s transition to free-to-play. Top-performing teams relied on tree boosting methods, including XGBoost, to secure winning outcomes [15].
Interpretability
One of XGBoost’s standout features is its ability to combine strong predictive performance with clear insights. Unlike deep learning models, often criticized as "black boxes", XGBoost highlights which player behaviors – like active duration, play count, or consecutive play ratio – most influence churn predictions [3][14]. This transparency helps developers understand not just when players might leave but also why.
"Many conventional machine learning methods have good interpretability (such as the clear decision path for decision tree and the feature importance for boosting model), but has shortcomings in data representation and generalization." – Decision Support Systems [14]
Training Time
While XGBoost delivers exceptional accuracy, it demands more computational power compared to simpler models like logistic regression. For datasets exceeding 80 million records, resource requirements can become substantial [2]. To address this, developers often use techniques like Random Under-Sampling (RUS) to reduce training time without sacrificing accuracy [7].
Scalability
XGBoost is built with scalability at its core. Its documentation emphasizes its design goal: "to push the extreme of the computation limits of machines to provide a scalable, portable and accurate library" [12]. By employing efficient split-finding algorithms, it quickly calculates structure scores for potential splits, even when working with massive datasets. This makes it particularly well-suited for freemium games, where millions of daily active users generate large volumes of data [14][15].
Suitability for Freemium Game Data
Freemium games often face challenges like imbalanced datasets and high early churn rates. XGBoost handles these complexities effectively, capturing non-linear relationships in behavioral data – such as session intervals and in-game purchases – that simpler models might overlook [3]. Additionally, because freemium games lack formal subscription cancellations, churn is typically defined using Observation Periods (OP) and Churn Prediction Periods (CP). XGBoost’s flexibility in working with diverse input features makes it a powerful tool for these scenarios [3].
Up next, we’ll explore how Support Vector Machines approach churn prediction.
sbb-itb-fd4a1f6
4. Support Vector Machines (SVM)
Support Vector Machines (SVM) rely on a hyperplane to distinguish churners from non-churners. By using kernel functions, they can also capture more intricate, non-linear patterns in player behavior, making them a versatile tool for analyzing complex data sets [7].
Accuracy
SVM has shown promising results in churn prediction. For instance, one study focusing on high-value players reported an accuracy of 80.17%, with an AUC of 0.912 and a sensitivity of 84.62%. Another smaller study with 418 players achieved an impressive 95% accuracy. However, when compared to ensemble methods like Random Forest (AUC 0.930) and XGBoost (AUC 0.915), SVM was slightly outperformed in similar settings [7][16].
Interpretability
While the basic concept of SVM – separating two classes with a decision boundary – is relatively simple, the complexity increases when non-linear kernels are introduced. These kernels map data into higher dimensions to identify intricate patterns, but this also makes the decision boundaries harder to visualize or explain. As a result, SVM is less transparent than models like decision trees or logistic regression [7].
Training Time
SVM’s computational requirements can pose challenges, especially for freemium games. Non-linear kernels, in particular, demand substantial processing power, leading to longer training times. For example, when analyzing logs from a storytelling game with over 80 million players, researchers often train SVM models on smaller data samples to avoid prohibitive computational costs. Additionally, SVM requires data to be centered and scaled before training, adding an extra preprocessing step that tree-based models typically skip [2][7].
Scalability
Scalability is a notable limitation for SVM in the context of freemium games. With millions of active users, SVM often struggles to meet the rapid training and inference demands required for real-time predictions [2]. This limitation makes it less suitable for large-scale applications, pushing teams to favor models that can handle the scale and speed necessary for real-time decision-making [11]. Consequently, SVM is better suited for smaller, high-value player segments rather than broad early churn prediction.
Suitability for Freemium Game Data
SVM shines in specific scenarios, particularly when targeting high-value players where losing a customer carries a significant cost [7]. Its ability to pinpoint borderline churners makes it a valuable tool for retention campaigns. However, for early-stage churn prediction – where player behavior is unpredictable and data volumes are massive – the computational demands of SVM can outweigh its advantages [2][13]. Moreover, the model’s performance hinges on careful tuning of hyperparameters like the regularization parameter (C) and Gamma, adding another layer of complexity [7].
Next, we’ll explore how Neural Networks tackle the challenge of churn prediction.
5. Neural Networks
In the competitive world of freemium games, where early player churn can make or break success, neural networks provide a powerful way to analyze player behavior. Specifically, Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) models shine when it comes to understanding sequences of player actions. Unlike static models, these architectures excel at identifying patterns over time. For example, RNNs are particularly adept at learning sequential behaviors, making them invaluable in freemium games where player activity can range from daily logins to sporadic sessions[17].
Accuracy
When configured properly, neural networks can deliver highly accurate predictions. For instance, a Dynamic Bidirectional LSTM model achieved an impressive 89.90% accuracy with an F1-score of 85.48% in predicting player retention[17]. Additionally, using neural networks as meta-learners in ensemble approaches – combining outputs from models like Logistic Regression and SVM – has resulted in accuracies as high as 92% when analyzing public API data[5]. However, it’s worth noting that simpler models like Random Forests have reached even higher accuracy levels, sometimes up to 97%[1][9]. Despite this, neural networks hold a unique advantage: their ability to process raw telemetry data directly, bypassing the need for extensive manual feature engineering.
Interpretability
One of the biggest challenges with neural networks is their "black box" nature. While they excel at uncovering complex patterns in player behavior, they don’t easily reveal the why behind those patterns[3]. This lack of transparency can be a stumbling block for game designers who need actionable insights – like deciding when to offer in-game rewards or send personalized marketing messages. In contrast, models like Random Forests or Logistic Regression are much easier to interpret, clearly highlighting which factors, such as time spent in-game or session frequency, contribute to player churn.
Training Time and Scalability
Training neural networks can be resource-intensive and time-consuming, especially when working with massive datasets. For example, analyzing over 80 million player records collected over four years has been described as "very computationally intensive"[2]. This can pose a problem for games that require quick, real-time predictions, especially given that around 61.81% of players churn within their first 24 hours[2]. To mitigate these challenges, developers often focus on shorter timeframes (e.g., 1–7 days of data) or work with smaller samples rather than processing an entire database all at once[2].
Neural networks are also well-suited for handling large-scale datasets, but they require careful planning. For instance, games that add 200,000 new players daily must implement fully automated data pipelines to keep these models updated[2]. Additionally, to manage the variability in player session lengths – a common issue in freemium games – techniques like zero-padding combined with dynamic RNN architectures are often used. These methods standardize input data while preserving critical information[17].
Suitability for Freemium Game Data
Neural networks are particularly effective at extracting layered representations from high-dimensional telemetry data, making them a strong choice for analyzing complex player behaviors[17]. However, for smaller games or situations where clear retention strategies are needed, the added complexity of neural networks might not be worth the slight performance improvement over simpler, more interpretable models[3]. In many cases, the optimal approach is to integrate neural networks within ensemble models. This allows developers to combine the pattern-recognition strengths of neural networks with the transparency of traditional algorithms[5].
These insights highlight the trade-offs between the power of neural networks and the practical challenges of their implementation in freemium games.
Pros and Cons
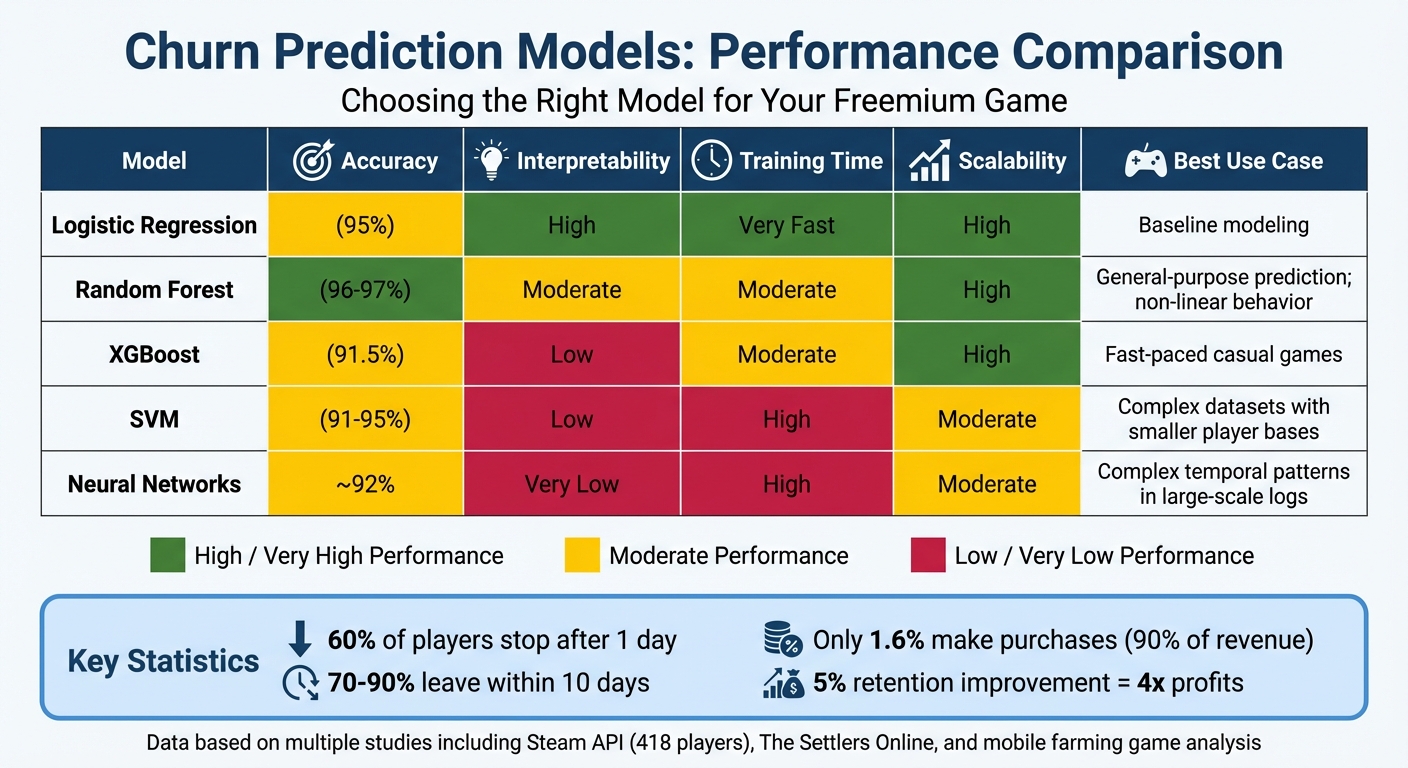
Churn Prediction Models Comparison: Accuracy, Speed, and Best Use Cases for Freemium Games
After diving into the details, let’s break down the strengths and limitations of each churn prediction model. Picking the right model for your freemium game comes down to balancing factors like accuracy, ease of interpretation, training speed, and scalability. Here’s a closer look at what each model brings to the table.
Logistic Regression is a solid starting point. It’s highly interpretable, showing exactly which player behaviors contribute to churn by modeling log-odds as a linear combination of variables[7]. It’s quick to train and handles scaling well, which makes it a great choice when resources are tight or when you need clear, explainable predictions. However, its accuracy is only moderate compared to more advanced models.
Random Forest is often a standout for freemium games, offering excellent accuracy[1]. It automatically identifies important features, ignores irrelevant ones, and doesn’t require feature scaling[7]. While it highlights which features are influential, it doesn’t clearly show how they interact, which limits its interpretability. Training time is moderate, but the payoff in prediction quality is often worth it.
XGBoost is a powerhouse for reducing loss through iterative gradient descent, making it a strong option for games where players churn quickly[7]. However, it demands careful tuning of hyperparameters and is less interpretable than simpler models.
To make things easier, here’s a comparison table summarizing each model’s performance and best-fit scenarios:
| Model | Accuracy | Interpretability | Training Time | Scalability | Best Use Case |
|---|---|---|---|---|---|
| Logistic Regression | Moderate (95%) | High | Very Fast | High | Baseline modeling[7][16] |
| Random Forest | Very High (96–97%) | Moderate | Moderate | High | General-purpose prediction; non-linear behavior[1][7] |
| XGBoost | High (91.5%) | Low | Moderate | High | Fast-paced casual games[7] |
| SVM | Moderate/High (91–95%) | Low | High | Moderate | Complex datasets with smaller player bases[7] |
| Neural Networks | Approximately 92% | Very Low | High | Moderate | Complex temporal patterns in large-scale logs[16] |
Support Vector Machines (SVMs) shine when it comes to detecting intricate patterns using kernel functions, achieving competitive accuracy[5][7]. However, their long training times make them less practical for the massive data volumes typical of freemium games[7].
Neural Networks are excellent at recognizing patterns in sequential or time-based data. However, they’re not transparent and require significant pre-processing and computational resources[3]. These factors make them better suited for large-scale logs where capturing complex patterns is critical.
Each model has its strengths, but the right choice depends on your game’s unique data and prediction needs.
Conclusion
Picking the right churn prediction model can make or break your freemium game’s revenue. Considering that around 90% of mobile game revenue comes from in-app purchases[3], keeping players engaged isn’t just important – it’s essential.
As we’ve seen, model performance plays a huge role in shaping retention strategies. For many freemium games, Random Forest often stands out. Its ability to deliver high accuracy and detect churn early makes it a go-to choice. For example, in The Settlers Online, using Random Forest with sliding windows led to an impressive 97% prediction accuracy[1]. This level of precision allows developers to act before players check out for good.
That said, Logistic Regression has its place too. It’s especially useful when you need quick insights or simple explanations. With about 95% accuracy[5], it’s a reliable option for games with limited data or when building a baseline model. In casual games, where the majority of players churn within 10 days[3], the speed and simplicity of Logistic Regression can outweigh the need for more complex models.
Timing also plays a critical role. In casual storytelling games, for instance, 61.81% of players churn within just 24 hours[2]. This calls for fast predictions and actionable insights. As researcher Seungwook Kim explains:
"A small number of well-chosen features used as performance metrics might be sufficient for making important action decisions"[3]
Instead of overloading your model with excessive features, focusing on key metrics like session frequency and playtime can yield better results.
Ultimately, the best model depends on your game’s genre, player behavior, and data scale. Strategy games, for example, benefit from Random Forest’s ability to track gradual disengagement, while casual games thrive with faster models that enable timely retention offers. By aligning the model to your game’s unique needs, you can create smarter, revenue-driven interventions that keep players coming back.
FAQs
How do churn prediction models help retain players in freemium games?
Churn prediction models analyze player data – like playtime, session length, and the gaps between sessions – to pinpoint users who may be on the verge of leaving the game. By spotting these trends, developers can step in early and re-engage these players with personalized incentives. This could mean offering free in-game currency, exclusive deals, or customized messages designed to bring them back.
These models give developers the tools to make smarter, data-backed decisions, helping to maintain player interest and boost retention rates. When used effectively, they can strengthen player loyalty and increase the overall lifetime value of your audience.
How do Random Forest and XGBoost differ for predicting player churn?
Random Forest and XGBoost are both ensemble models, but they take very different approaches to building and combining decision trees. These differences play a significant role in how well they perform when predicting churn.
Random Forest creates each decision tree independently by using a random subset of the data and then averages their predictions. This independence makes it highly resistant to overfitting, requires minimal fine-tuning, and offers straightforward interpretation. However, it can struggle when dealing with highly imbalanced churn datasets and may eventually hit a ceiling in terms of predictive accuracy.
XGBoost, in contrast, builds its trees sequentially, with each new tree focusing on correcting the errors made by the previous ones. This iterative process, combined with advanced features like regularization and tree pruning, often leads to better accuracy – especially when the dataset includes well-crafted features. That said, XGBoost requires careful hyperparameter tuning to avoid overfitting and is more sensitive to these adjustments. Still, it’s incredibly efficient for working with large datasets due to its speed optimization.
In summary, both models bring unique strengths to the table: Random Forest is straightforward and stable, while XGBoost shines in precision and adaptability for uncovering complex churn patterns.
Why is logistic regression a popular choice for churn prediction in freemium games?
Logistic regression is a popular choice for churn prediction, thanks to its balance of reliability and simplicity. It delivers solid performance while being light on computational demands, making it perfect for quick deployment and analysis.
What’s more, logistic regression pinpoints the factors driving player churn, offering insights that game developers can act on. Its straightforward nature makes it an excellent starting point before diving into more advanced modeling techniques.